I conducted some desk research today which I hoped would either reinforce or eliminate my hunch that general interest in all-things-tech is growing. Anyone who has read Daniel Kahneman’s fantastic book on the role of intuition in such judgments, will know that the only way that I can (possibly!) get away from making bold claims like “the general population are becoming more curious about the mechanisms of tech” is by somehow providing a statistical proof.
Enter Google Trends, and some rough – yet hopefully revealing – investigating on my part. Here’s where I got to:
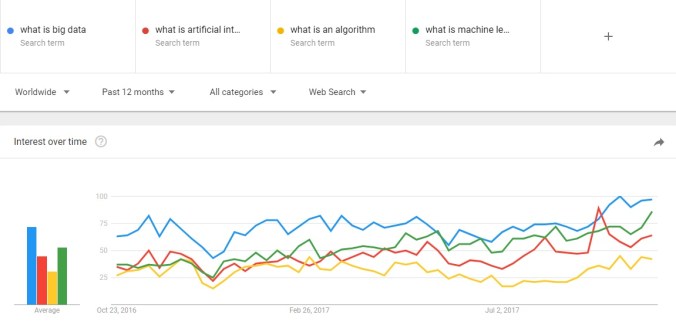
- The popularity of the search term “what is Big Data” has increased by 54%
- The popularity of the search term “what is an algorithm” has increased by 56%
- The popularity of the search term “what is artificial intelligence” has increased by 83%
- The popularity of the search term “what is machine learning” has increased by 132% (!)
- The overall popularity of these tech-related search terms increased by 78%.
All the figures are over a 12-month period (Oct 2016 – Oct 2017), and my increases are based on Google Trends’ “interest over time measure” which assigns a value relative to peak popularity. It is also interesting to look at these same search terms over a longer period (see 3-year and 5-year charts) where the same trajectory can also be seen quite neatly.
My methodology, of course, is unashamedly unsophisticated. The list of terms I have used is certainly not exhaustive, and I’m aware that words like “algorithm” are not exclusive to the tech lexicon. I figured that the “what is” prefix would generally denote a novice search, and I would probably defend this as an as-good-as-anything-else, finger-in-the-air way to gauge if searches are from new, enquiring minds. Nevertheless, as discussed, my objective was to find some indication that my original intuition was correct. This is not intended to reflect a rigorous and conclusive study…
So, what does it mean? Well, it seems to confirm something that we all think we already know. Namely, that tech is migrating from the nerdy peripheries to center stage. And if we can reasonably assume these searches imply a quest for knowledge, then we might use this to speculate about a future where tech knowledge is decentralized, and better diffused throughout broader society.
Instinctively, this feels like a good thing. So many ethical discussions about tech focus on worries about privacy, manipulation, and the imbalance of power. When we talk about tech in society, the conversation can often turn to doomsday scenarios. But the upward lines on these charts might tell us something different. An interested and informed general population might help mitigate against ill effects in the next few years.
Furthermore, it’s easy to forget the many, many good things that are happening in tech which – with an increasingly engaged population – could truly benefit the whole of society. Just casually browsing the news this week, two very different stories caught my eye. The first was about 28-year old James Green, who believes his life was saved by his Apple Watch, which alerted him to a sudden and extreme increase in his heart rate and prompted him to seek urgent help for what turned out to be a deadly pulmonary embolism. The second was about Pinchas Gutter, a holocaust survivor and participant in the New Dimensions in Testimony project, which helps keep history alive by allowing (in this case) visitors to the Museum of Jewish Heritage in Toronto to interact with an image of Mr. Gutter, and ask questions about his experiences during the Nazi occupation of Poland.
In both cases – but in very different ways – technology, algorithms, data, and machine learning are being employed to save us. To increase our awareness in ways that (I believe) can only be described as positive. The more we all understand about how these technologies work, the more likely it is that they will survive, thrive and new, similar ideas will evolve to the advantage of all of us.
This is, obviously, an optimistic view. But I think when we’re talking about ethics it can be important not to artificially suppress a well-founded glimmer of hope where it occurs. Only time how will tell how it will all play out.