Facebook have been in a press a lot this week, and there have been a flurry of articles asking how they might be brought back from the brink. The New York Times asked a panel of experts “How to Fix Facebook?”. Some of the responses around the nature of –and limitations to– our user interactions on the social network struck me as very interesting.
Jonathan Albright, Research Director at Columbia University’s Tow Center for Digital Journalism, writes:
“The single most important step Facebook — and its subsidiary Instagram, which I view as equally important in terms of countering misinformation, hate speech and propaganda — can take is to abandon the focus on emotional signaling-as-engagement.
This is a tough proposition, of course, as billions of users have been trained to do exactly this: “react.”
What if there were a “trust emoji”? Or respect-based emojis? If a palette of six emoji-faced angry-love-sad-haha emotional buttons continues to be the way we engage with one another — and how we respond to the news — then it’s going to be an uphill battle.
Negative emotion, click bait and viral outrage are how the platform is “being used to divide.” Given this problem, Facebook needs to help us unite by building new sharing tools based on trust and respect.”
Kate Losse, an early Facebook employee and author of “The Boy Kings: A Journey into the Heart of the Social Network”, suggested:
“It would be interesting if Facebook offered a “vintage Facebook” setting that users could toggle to, without News Feed ads and “like” buttons. (Before “likes,” users wrote comments, which made interactions more unique and memorable.)
A “vintage Facebook” setting not only would be less cluttered, it would refocus the experience of using Facebook on the people using it, and their intentions for communication and interaction.”
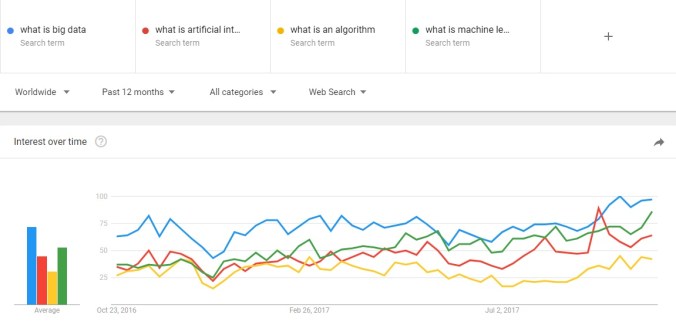
According to recent reports, “reactions” are being algorithmically prioritized over “likes”. Why? Well, we might suppose, for the same reason most new features are developed: more and greater insight. Specifically, more insight about our specific emotions pertaining to items in our newsfeed.
Understanding the complexity of something we type in words is difficult. Systems have to understand tone, sarcasm, slang, and other nuances. Instead, “angry”, “sad”, “wow”, “haha”, and “love” make us much easier to interpret. Our truthful reactions are distilled into proxy emojis.
I see two problems with this:
- The first is that we are misunderstood as users. Distilling all human emotions/reactions into five big nebulous ones is unhelpful. Like many of the old (and largely discredited) psychometric tests questions, these reactions allow us to cut complexity out of our own self-portrayal. This means that, down the line, the data analytics will purport to show more than they actually do. They’ll have a strange and skewed shadow of our feelings about the world. We’ll then, consequently, be fed things that “half match” our preferences and – potentially –change and adapt our preferences to match those offerings. In other words, if we’re already half-misinformed, politically naïve, prejudiced etc., we can go whole hog…
- The second problem is that discouraging us from communicating our feelings using language, is likely to affect our ability to express ourselves using language. This is more of a worry for those growing up on the social network. If I’m not forced to articulate when I think something is wonderful, or patronizing, or cruel, and instead resort to emojis (“love” or “angry”), then the danger is that I begin to think in terms of mono-emotions. With so many young people spending hours each day on social media, this might not be as far-fetched as it sounds.
If there’s a question-mark over whether social network’s cause behavior change, then it’s fine to be unbothered about these prospects, but given Silicon Valley insiders have recently claimed that the stats are showing our minds “have been hijacked”, then perhaps it’s time to pay some heed to these mechanisms of manipulation.